
Bei der täglichen Recherche ist uns eine Unregelmäßigkeit der Funktionsweise von „robots.txt-Tester“ und „Abruf durch Google“ in den Google Webmaster Tools aufgefallen. Dies bewegte uns zu einer genaueren Beobachtung von Googles Crawling-Funktionen. Dabei haben wir einen Bug bei der Auswertung der User Agents innerhalb von Webmaster Tools festgestellt, wodurch falsche Schlussfolgerungen gezogen werden könnten. Das Problem tritt beim Zusammenspiel der Module „robots.txt-Tester“ und „Abruf wie durch Google“ auf.
Um den Bug zu reproduzieren, muss folgendes Setup aufgebaut werden:
Testschritt 1
Ein Beispielordner muss für den Googlebot durch eine „disallow“-Direktive in der robots.txt blockiert und zugleich für den Googlebot Mobile durch „allow“ zugänglich gemacht werden.
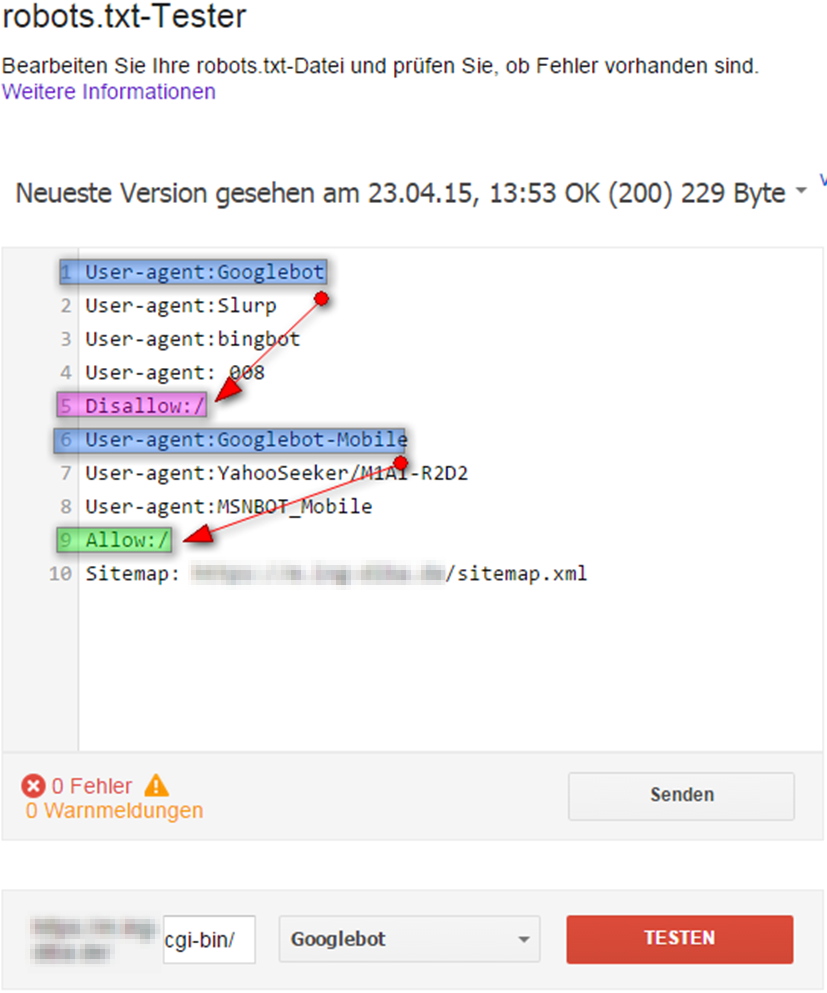
Jetzt lässt sich mit dem „robots.txt-Tester“-Tool des Google Webmaster Tools prüfen, ob und wie die vorhandenen Anweisungen von verschiedenen Googlebots interpretiert werden.
Geprüft wird hier der Zugang zum Ordner /cgi-bin/:
Testschritt 2
Prüfung mit dem Googlebot:
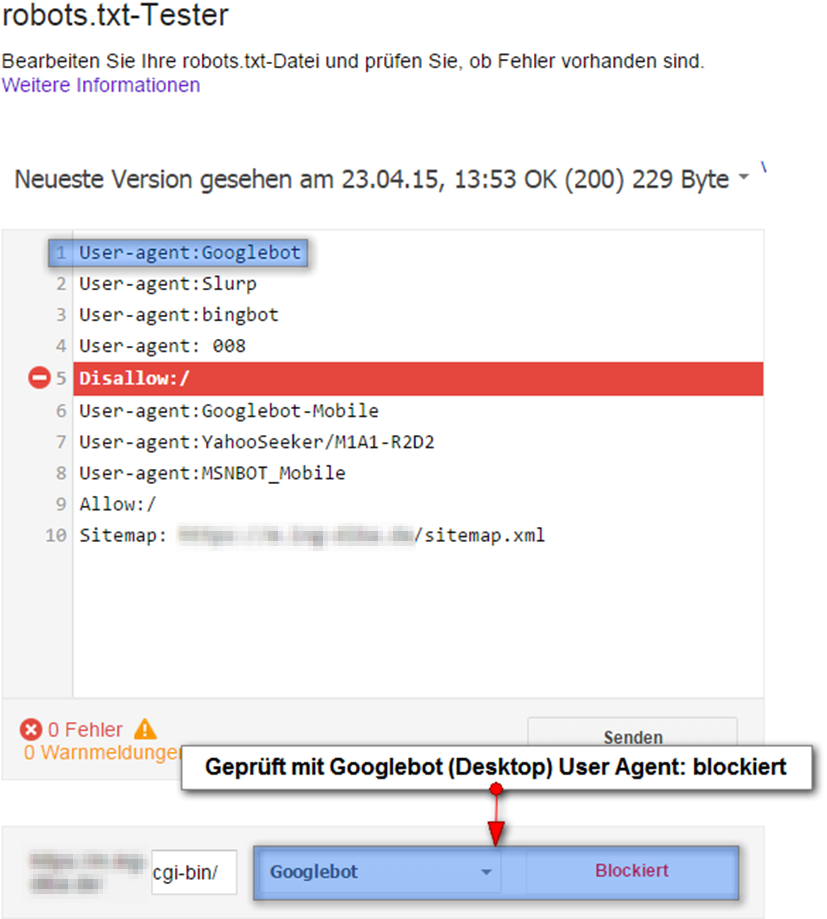
Das Ergebnis der Prüfung ist erwartungsgemäß: Zugang nicht erlaubt.
Testschritt 3
Es folgt die Prüfung mit dem Googlebot Mobile:
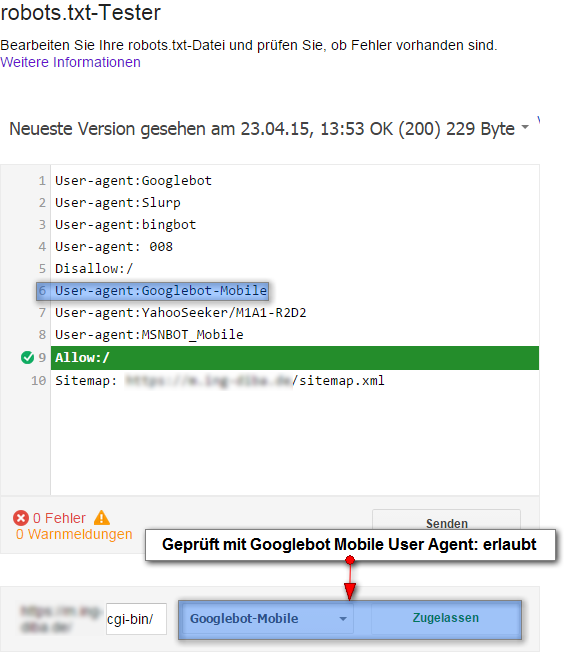
Hier werden die Erwartungen auch bestätigt: der Zugang ist erlaubt.
Testschritt 4
Nun wird der Beispiel-Ordner mit dem „Abruf wie durch Google“-Tool aufgerufen. Hier kommt die erste Überraschung, denn diesmal scheint für keinen User Agent der Zugriff erlaubt zu sein:
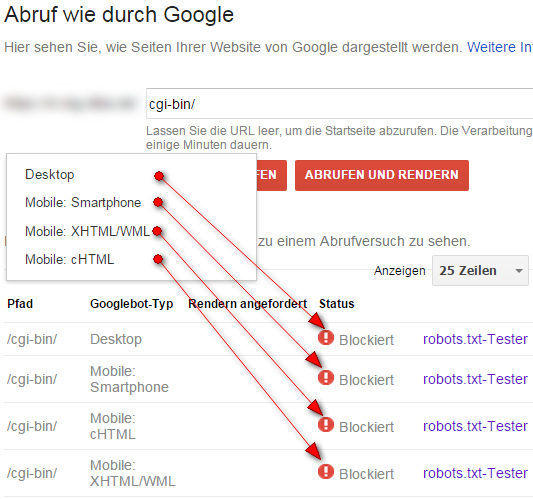
Dass der Abruf des Ordners mit dem Googlebot Desktop nicht klappt, war zu erwarten, denn der Googlebot ist ja mit durch die „disallow“-Direktive ausgesperrt. Doch warum schaffen es die drei mobilen Bots nicht, in den Ordner reinzukommen, wo doch für Googlebot Mobile der Zugang gewährt wurde?
Nun blendet das Tool zu jedem Versuch auch einen direkten Link zum „robots.txt-Tester“ ein, damit man die Entscheidung des Bots nachvollziehen kann. Wir nutzen zur weiteren Analyse den Umstand, dass der Aufruf durch diesen Link parametrisiert erfolgt – wir können also sehen, welcher User Agent jeweils geprüft wird.
Testschritt 5
Der Abruf des Ordners mit dem Desktop Googlebot bietet wenig Überraschendes – dabei ist der Parameter in der URL-Zeile zu sehen: „useragent=Googlebot“.
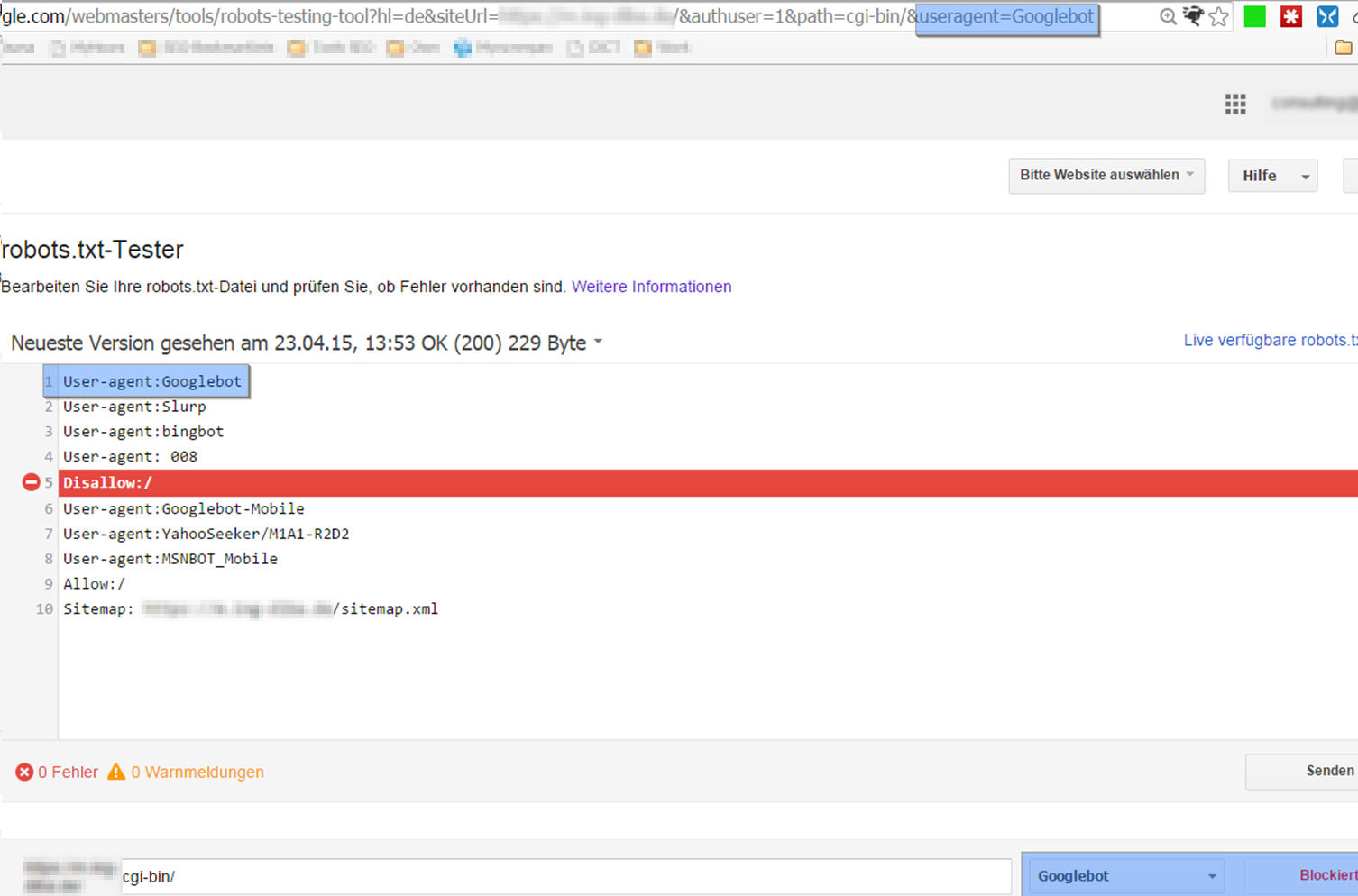
Der Grund für den gescheiterten Abrufversuch ist die markierte, blockierende Anweisung in der robots.txt. Der User Agent ist ersichtlich in der URL und entspricht dem Crawler, der geblockt wird.
Testschritt 6
Als Nächstes wird der Abrufversuch mit dem User Agent „Mobile: Smartphone“ geprüft. Da wir den Link „robots.txt-Tester“ eines gescheiterten mobilen Abrufversuchs testen, erwarten wir natürlich, dass hier auch ein mobiler Crawler geprüft wird. Zu unserem Erstaunen ändert sich dabei aber der Parameter „useragent“ in der URL nicht: er bleibt „useragent=Googlebot“.
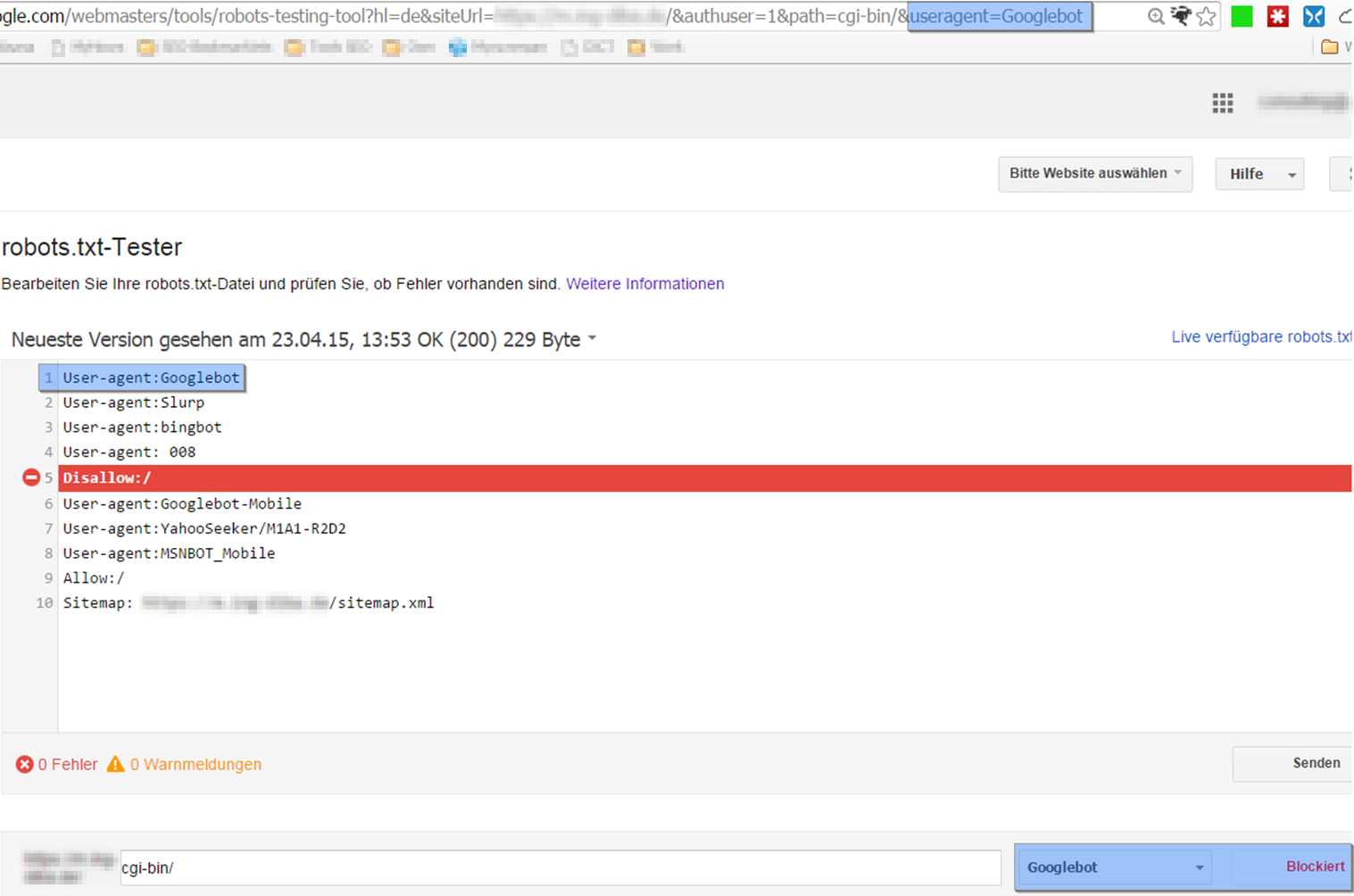
Gemäß der robots.txt-Anweisung wird hier der Zugriff für den Googlebot gesperrt, was aber nicht unseren Erwartungen entspricht.
Testschritt 7
Jetzt ist der Abrufversuch mit der Option „Mobile: cHTML“ dran. Dieser Versuch ist zuvor im „robots.txt-Tester“ blockiert worden, wie in Abb. 4 zu sehen. Doch dieses Mal wird er erlaubt:
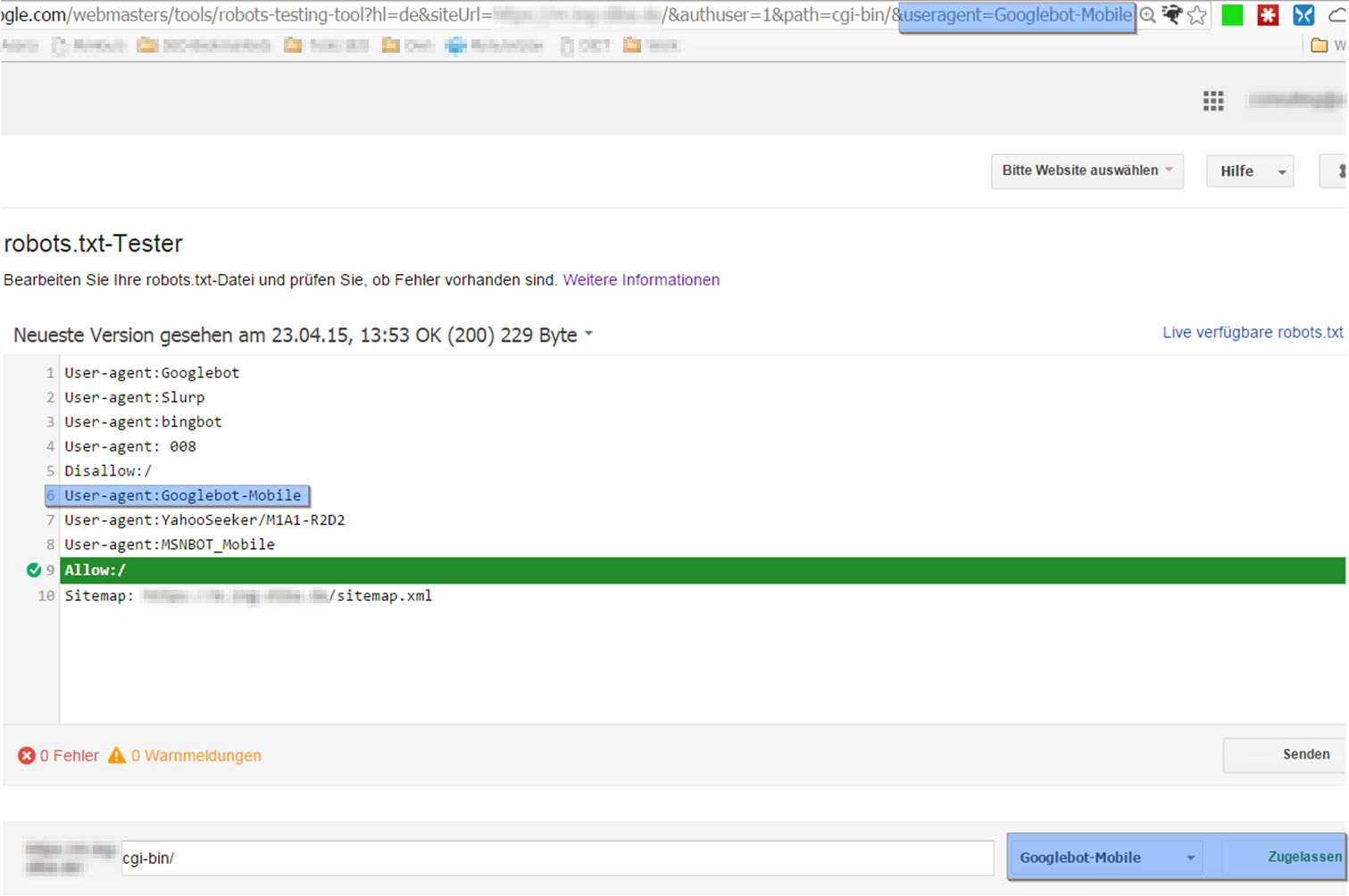
Obwohl der Abrufversuch mit dem „Abruf wie durch Google“–Tool kurz zuvor blockiert wurde, zeigt der „robots.txt-Tester“ korrekt an, dass er erlaubt ist.
Testschritt 8
Als Letztes wird der zuvor gescheiterte Abrufversuch mit der Option „Mobile: XHTML/WML“ validiert:
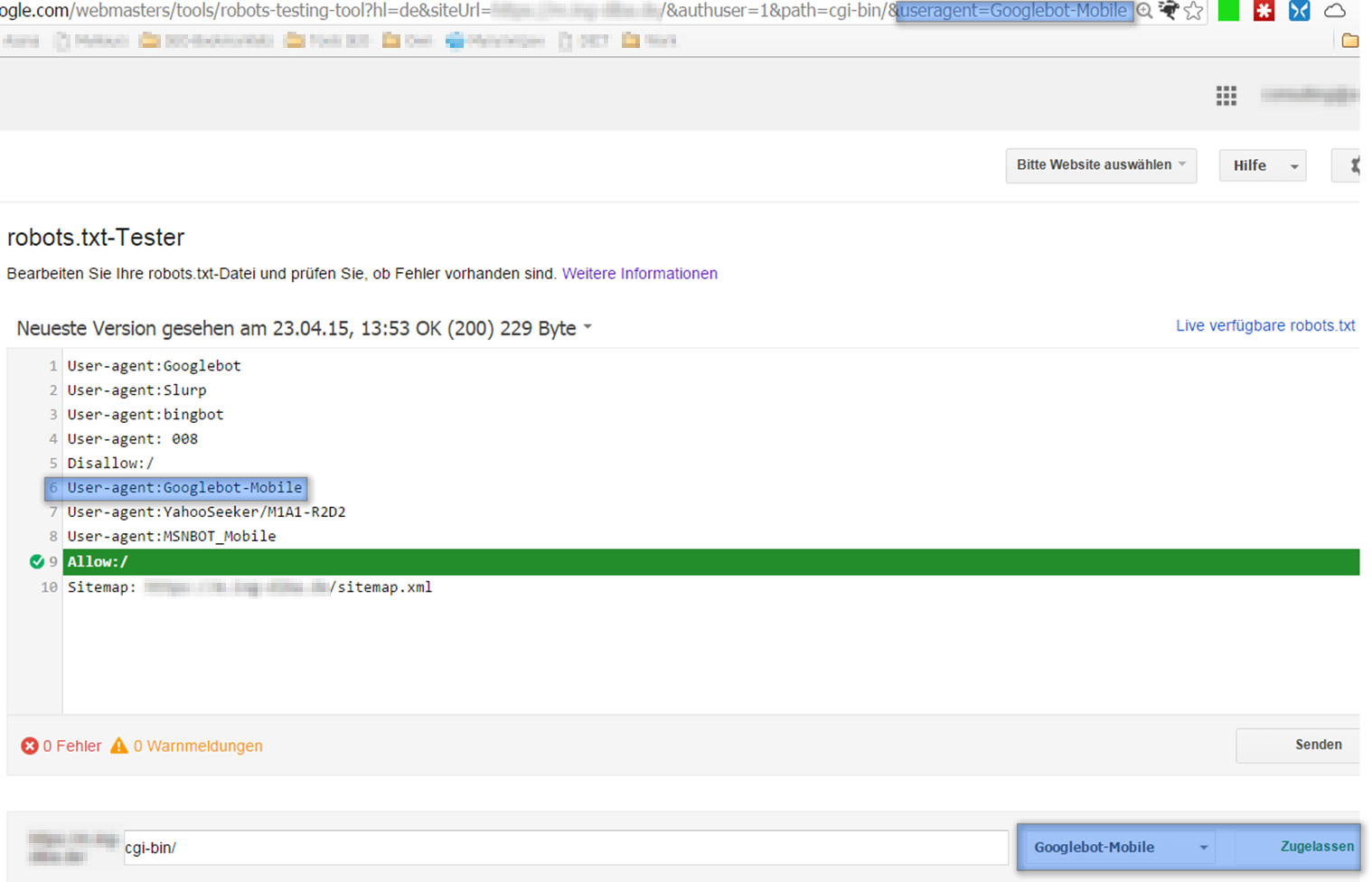
Das Ergebnis der Validierung: Obwohl der Abrufversuch mit dem „Abruf wie durch Google“-Tool blockiert wurde, zeigen die Validierungsseite sowie die User Agent-Bezeichnung in der URL der Validierungsseite erneut, dass er erlaubt ist.
Fazit
Googles „Abruf wie durch Google“ und „robots.txt-Tester“ spielen nicht einwandfrei zusammen. Was das eine Tool als Erlaubnis interpretiert, ist für das andere eine Sperre. Zu guter Letzt scheint nur der „robots.txt-Tester“ seine Aufgabe korrekt zu erfüllen. Ärgerlich ist das deshalb, weil durch diesen Bug die Funktion „Abruf wie durch Google“ überall dort eingeschränkt ist, wo man den mobilen Bot in der „robots.txt“ separat behandelt.



